Любопытный модуль Drupal 7 HTML import. Если хорошо структурированный стилями заголовков документ ворда сохранить в формате HTML, а затем хорошенько почистить с помощью Dreamweaver, то можно получить ноды из заголовков.
Сокращенный перевод описания, комментарии после развертывания, настройки и проверки работоспособности. Редакция от 21.12.2024.
Создан 19.01.2021 13:17:03

Введение
Модуль HTML import предназначен для разделения одного большого HTML–документа на структурированную книгу Drupal, в которой соблюдается иерархия уровней заголовков (исходного документа).
Модуль HTML import работает:
- с HTML, экспортированным из <Word> (проверено);
- с HTML–документом, преобразованным из PDF;
- а также HTML–документом, экспортированным из Adobe InDesign (не проверено).
Цель (purpose) данного модуля — предоставить альтернативу устаревшим документам, отвечающую требованиям доступности WCAG (www.w3.org/Translations/WCAG20–ru/WCAG20–ru–20130220/). Преобразование документов в HTML также упрощает полнотекстовый поиск.
Что нового в HTML import 2.x?
Новые возможности версии HTML import 2.x:
- протестирован под PHP 7;
- тщательно протестирован под GovCMS 7;
- добавлен пример субмодуля (example sub–module), автоматически создающий страницы родительской книги (публикации — тип контента publication) и книги (раздел публикации — тип контента publication section), чтобы не настраивать их самостоятельно (проверено, работает);
- поддержка (модуля) Entity reference;
- поддержка (модуля?) Workbench;
- контент–администраторы могут указывать язык импортируемых страниц, если включен модуль локализации;
- ссылки привязки (anchor reference links) восстанавливаются с использованием псевдонимов URL–адресов, если таковые доступны;
- некоторые другие мелкие исправления ошибок и улучшения.
Интеграция с Workbench
Стартовала работа по интеграции HTML Import и Workbench для обеспечения полной поддержки рабочего потока контента (full content workfow support). Вскоре будут поддерживаться такие функции, как запланированная (scheduled) публикация (отмена публикации), проверка контента и т.д.
govCMS
Модуль HTML import совместим с распределением (distribution) Australian Government's govCMS и может использоваться для простого (easily) импорта отчетов для агентств.
Для лучшей совместимости пользователям GovCMS рекомендуется использовать ветку 7.x–2.x–dev модуля HTML Import. Данный модуль был успешно протестирован на GovCMS 7.x–2.0–beta3.
Данный модуль применялся для создания HTML–версий отчетов в интересах государственных учреждений Австралии. Примеры предыдущих проектов:
- Department of Prime Minister and Cabinet;
- Australian Crime Commission;
- Department of Prime Minister and Cabinet and Department of Health;
- Torres Strait Regional Authority;
- Department of Infrastructure;
- National Blood Authority;
- Australian Trade and Investment Commission (Austrade);
- Inspector–General of Intelligence and Security (IGIS);
- Australian Commission for Law Enforcement Integrity (ACLEI).
Однако, аборигены не спят... Списочек госучреждений впечатляет. Спасибо островитянам, оплатившим разработку из собственного бюджета.
Спонсорская поддержка
Проект спонсируется XiNG Digital — xing.net.au (этим тоже огромное человеческое спасибо. Из России с любовью) 🤣
Основные особенности HTML import
Основные особенности (features) модуля HTML import:
- позволяет пользователю указать уровни заголовков, по которым документ HTML разделяется (на отдельные фрагменты) и импортируется. Если в разделе (?) Heading level depth выбран H3, каждый H1, H2 и H3 станет отдельной страницей (нодой) в импортированной книге;
- импортирует изображения. Сканирует и фиксирует пути изображений, на которые ссылаются импортированные страницы;
- учитывает иерархию уровней заголовков исходного документа, восстанавливая ту же иерархию книг;
- сканирует и воссоздает справочные ссылки (reference links). Справочные ссылки в исходном HTML могут быть разделены на разные страницы книги после импорта. Модуль сканирует и повторно связывает справочные ссылки для сохранения целостности документа;
- сканирует и перемещает сноски (footnotes)/концевые сноски (endnotes). Если сноски/концевые сноски хорошо отформатированы (well–formatted), модуль сканирует и перемещает сноски/концевые сноски в разделы (sections), где на них есть ссылки, для облегчения чтения;
- соответствует требованиям доступности WCAG. Модуль сохраняет свойства доступности исходного HTML, такие как ALT текст;
- удаляет нежелательные символы <Word>, такие как «умные кавычки» в заголовках для создания чистого URL (clean URL);
XiNG Digital также разработала методы преобразования практически любого документа PDF в совместимый с WCAG 2.0 HTML, который может использоваться импортером документов.
Установка и настройка HTML import
Установка и настройка HTML import:
- Загрузить и включить HTML import, а также его зависимости, модули Book, Entity Reference, Entity API, Chaos tools, Feeds, Job Scheduler, Feeds Admin UI, File, Field, Field SQL storage, Field UI, File (Field) Paths, Image, QueryPath;
- Создать (или изменить) тип контента, к которому будут прикреплены страницы импортированной книги (это созданный субмодулем тип контента Publication). Данный тип контента должен содержать поле с машинным именем field_images. Указанное поле должно иметь одно значение и принимать только zip–файлы. Это поле не обязательно должно быть обязательным;
- Создать (или изменить) тип контента для импортированных страниц (это созданный субмодулем тип контента Publication section). Тип контента должен содержать поля:
- Сноски (Footnotes). Поле типа Long text, в котором будут храниться сноски/концевые сноски, на которые ссылается раздел (section);
- Импортированные изображения (Imported images). Файловое поле с машинным именем field_html_import_images, допускающее неограниченное количество значений и принимающее только требуемые форматы изображений. Поскольку этот модуль может импортировать большое количество файлов изображений, желательно, чтобы эти изображения хранились в каталогах, соответствующих их соответствующим (relevant to their corresponding) импортированным страницам. Модуль File (?eld) path позволяет назначать путь, такой как documents/[node:nid]/images;
- Родитель публикации (Publication parent). Поле Node reference с одним значением, позволяющим ссылаться только на тип контента, указанный на шаге 2 выше. Это поле позволит назначать иерархические псевдонимы URL импортированным страницам (НАХРЕН!!!);
- Перейти в Структура (Structure) ⇨ Импортеры каналов (Feeds importers) ⇨ Добавить импортер (Add importer) и выполнить следующие действия:
- Здесь пропущен шаг, см. рисунок ниже;
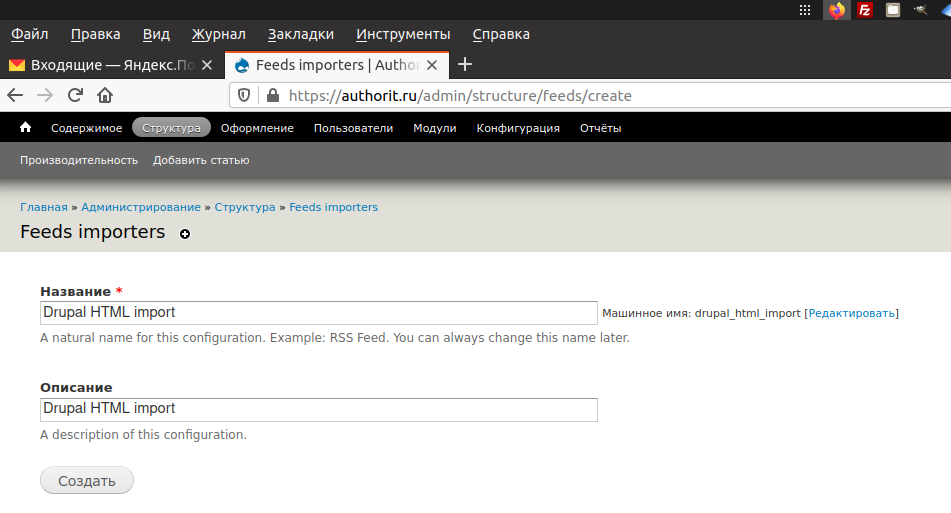
- Основные настройки (Basic settings). В списке Attach to content type выбрать тип контента Publication, созданного на шаге 2 (выше). В списке Periodic import выбрать Off;
- Сборщик (Fetcher) ⇨ Изменить (Change) — выбрать HTML Import Fetcher;
- Сборщик (Fetcher) ⇨ Настройки (Settings) — в текстовом поле Допустимые расширения файлов (Allowed ?le extensions) должны быть разрешены только расширения HTML, такие как «html»;
- Parser ⇨ Change — выбрать HTML Import Parser;
- Процессор (Processor) ⇨ Изменить (Change) — выбрать HTML Import Processor;
- Процессор (Processor) ⇨ Настройки (Settings) — выбрать в поле bundle тип содержимого Publication section в шаге 3 (выше). Включить вариант Update existing nodes. Text format должен быть Full HTML или его эквивалент (выбрать Filter HTML из соображений безопасности?);
- Процессор (Processor) ⇨ Сопоставление (Mapping). Title сопоставляется Title, Body сопоставляется Body, Footnotes сопоставляются Footnotes, а Book ID сопоставляется Publication parent — ссылка на узел по идентификатору узла (Node reference by node ID). Тоже неточности — наименования полей источника не всегда совпадают с целевыми, см. рисунок ниже;
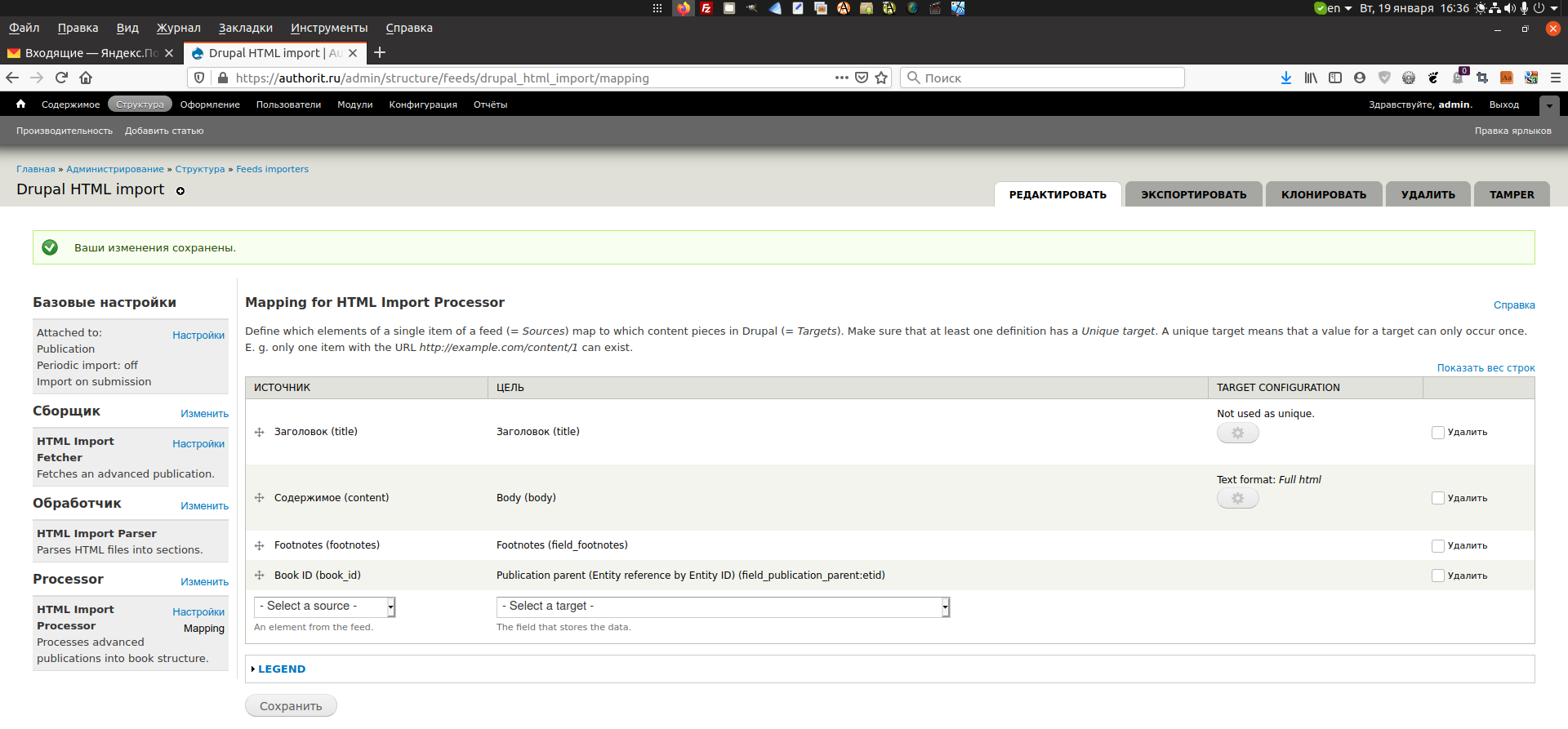
- Здесь пропущен шаг, см. рисунок ниже;
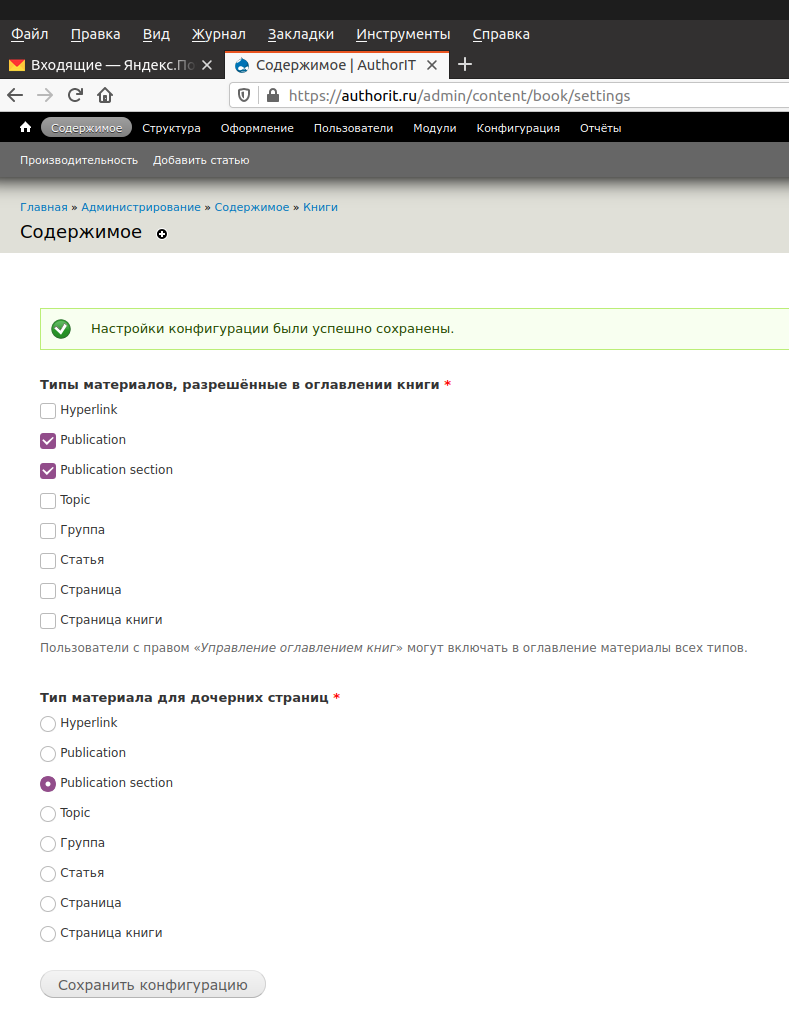
- Контент (Content) ⇨ Книги (Books) ⇨ Настройки (Settings) — установить Content types allowed in book outlines в Publication, Content type for child pages — в Publication section по шагам 2 и 3 выше (а вот это не слишком интересно, книги нам не нужны). Так не ругается, см. рисунок ниже;
- Создать новый контент с использованием типа, указанного на шаге 2 (т.е. Publication);
- Загрузить заархивированный каталог изображений в файл, созданный на шаге 2. Все файлы изображений должны храниться в каталоге, названном, например, images, а исходный HTML–код должен ссылаться на изображения в этом каталоге (пока не грузил);
- Обязательно преобразовать кодировку с помощью Kaboom;
- Загрузить исходный HTML–код в поле Файл в группе Поле канала (File ?eld under Feed ?eld group) — у автора Лента. Выбрать желаемую глубину уровня заголовка. При необходимости следовать инструкциям на экране для остальных полей.
- Сохранить и импортировать.
Некоторые соображения
Некоторые соображения:
- как книжка импортируется нормально:
- если через Microsoft™ Word, то могут быть проблемы со стилями и кодировкой, пришлось пересохранять в LibreOffice, чтобы получить UTF–8;
- если AuthorIT HTML, то нормально, когда теги головные не удаляется;
- картинки легли традиционно по FTP.
- отключил обязательность поля Publication parent в типе материала Publication section;
- в общем, работает.
Работа с Microsoft Word
Хорошо подготовленный документ Microsoft™ Word (очевидно, имеется в виду грамотное применение стилей заголовков) можно сохранить командой меню Сохранить как ⇨ Веб–страница с фильтром, а файл HTML можно легко импортировать с помощью модуля HTML import. Можно очистить исходный HTML–код от избыточного кода Microsoft™ Word с помощью Adobe Dreamweaver командой меню Команды ⇨ Исправить HTML–код Word.
Проверено. После сохранения с фильтрацией Dreamweaver находит и вычищает еще весьма приличное количество мусора.
Пример
Пример отчета, который возможно использовать для тестирования модуля HTML import.
Дополнительные замечания
Примечание 1 — Некоторые изменения в отображении импортированных страниц, такие как меню оглавления, навигация по книгам и сноски, могут потребовать настройки. Лучше всего начать с создания собственного экземпляра файла шаблона book–navigation.tpl.php в вашей теме/модуле.
Примечание 2 — Модуль HTML import привязан к памяти. Если у вас возникли проблемы при импорте файлов HTML, сначала проверьте лимит памяти PHP. Мы тестировали этот модуль с объемом памяти менее 256 МБ, не обнаружив проблем при импорте файлов HTML, преобразованных примерно из 200 в 300 страниц PDF. Однако рекомендуется увеличить лимит памяти PHP до 512 МБ в производственной среде, чтобы обеспечить достаточные ресурсы для других важных производственных веб–функций.
Примечание 3 — На этапе разработки этого модуля мы импортировали более 100 000 страниц, преобразованных из PDF, Microsoft™ Word и InDesign, на ряд веб–сайтов. Самый крупный из успешно импортированных документов содержит более 1000 страниц.
Примечание 4 — Модуль HTML import содержит небольшую утилиту, которая объединяет импортированные файлы и сохраняет содержимое HTML в виде «полнотекстового» текста на родительской странице книги. Это поле позволяет полнотекстовому поиску соответствовать как родительской странице, так и любой из ее дочерних страниц, если они содержат любое из искомых слов. Модуль Apache Solr Views может использоваться для предоставления очень полезной функции полнотекстового поиска.
Пример отчета, который можно использовать для тестирования этого модуля 847,36 КБ (drupal.org/files/example_4.zip).
