Библиотека взаимоувязанных документов, привязанная к отечественным стандартам разработки, проектирования и документирования, выполненная в многопользовательском глобально–сетевом варианте. В качестве движка применяется Drupal с минимально необходимым числом «контрибных» модулей и модулей ядра. Почти никакого программирования. Последовательность действий при подготовке и импорте контента в Drupal для организации нод, «портирование» ранее созданной и обкатанной библиотеки. Редакция от 09.11.2024.
Создан 14.12.2020 19:20:39
На западном фронте без перемен...

Подготовка HTML–контента
Подготовка HTML–контента — самая обычная и без особенностей. Публикация, изменение кодовой страницы с Win–1251 на UTF, компрессия, преобразование старых тегов под стандарты w3.org, удаление «сложносочиненных» тегов body и html. На выходе — компактный HTML–контент, последующая загрузка на сервер по FTP.
Подготовка XML или CSV–контента уже с особенностями. Чисто XML'ный импорт в Drupal проходит неважно, поскольку очень своеобразно скомпонован сам XML–файл после публикации в AuthorIT. Неприятность состоит в том, что все объекты — сиблинги, «братья и сестры», а по логике вещей объекты Book должны бы возглавлять иерархию. Понятно, что объекты в AuthorIT могут быть созданы отдельно и независимо друг от друга, но опубликованы они быть могут только в составе Book.
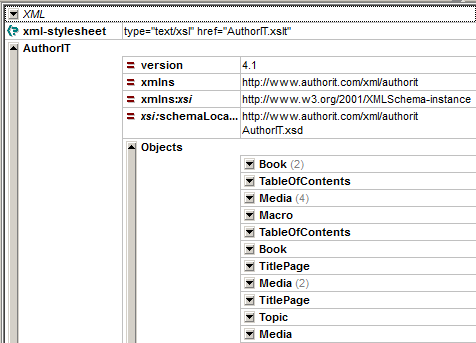
Разбирать такой XML–файл довольно сложно, а импортировать в Drupal катастрофично. Поэтому правильный путь — создание собственного XSLT–преобразования, что и потребовало минимального программирования. На выходе после применения XSLT–преобразования Altova XMLSpy выдает вот такую чудесную табличку, которую удобно сохранять в формате xlsx.
Поля таблички:
- самое первое поле содержит собственно контент каждого объекта Book, который практически невозможно вытащить из сырого XML–файла без XSLT–преобразования из–за не вполне объяснимой иерархии его объектов;
- поле Title — это заголовок создаваемой в ходе импорта страницы Drupal, ноды в Drupal'овской терминологии, соответствующей топику. Возможно, имеет смысл сделать уникальным именно поле Title;
- поле Body — это тело ноды, в которое подгружается контент соответствующего ноде топика. Можно подгружать текстом его прямо из XML–файла, но проще и удобнее забирать и внедрять HTML–контент в виде файлов–топиков, сгенерированных и заброшенных на сервер чуть ранее, простым оператором PHP include;
- поле path_alias — это алиас или псевдоним ноды. Любая нода по умолчанию получает системный адрес [DOMAIN]/node/xxxxxx, где иксы — уникальный ключ ноды (nid), создаваемый Drupal'ом. Для взаимно–однозначного соответствия номеру ноды назначается уникальный ключ топика Drupal как псевдоним, в результате чего ноду можно открыть иначе — [DOMAIN]/yyyyy, где игреки — ключ топика;
- поле guid — пока используется как уникальный идентификатор, но, наверное, разумно поменять его на Title, чтобы не двоить ноды при апдейте;
- поля Book Link Title и Book Link URL — это и есть сама матрица, связывающая множество топиков с одной книгой. Или один топик с множеством книг. Т.е. в КАКИХ Book какой Topic присутствует.
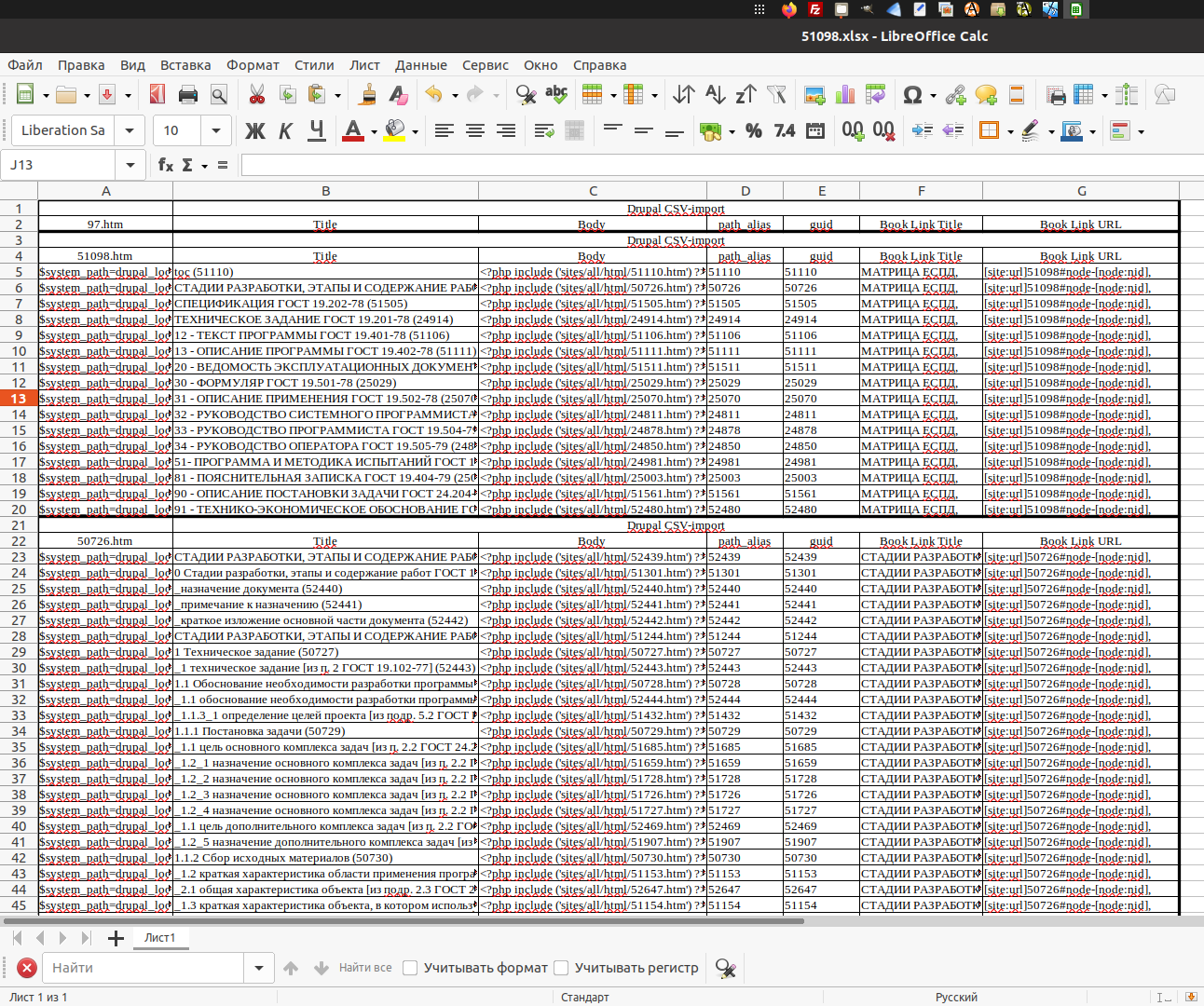
Далее эта табличка копируется сразу в две — XXXXX node update и XXXXX book update. И оставляется в покое.
Таблица node update
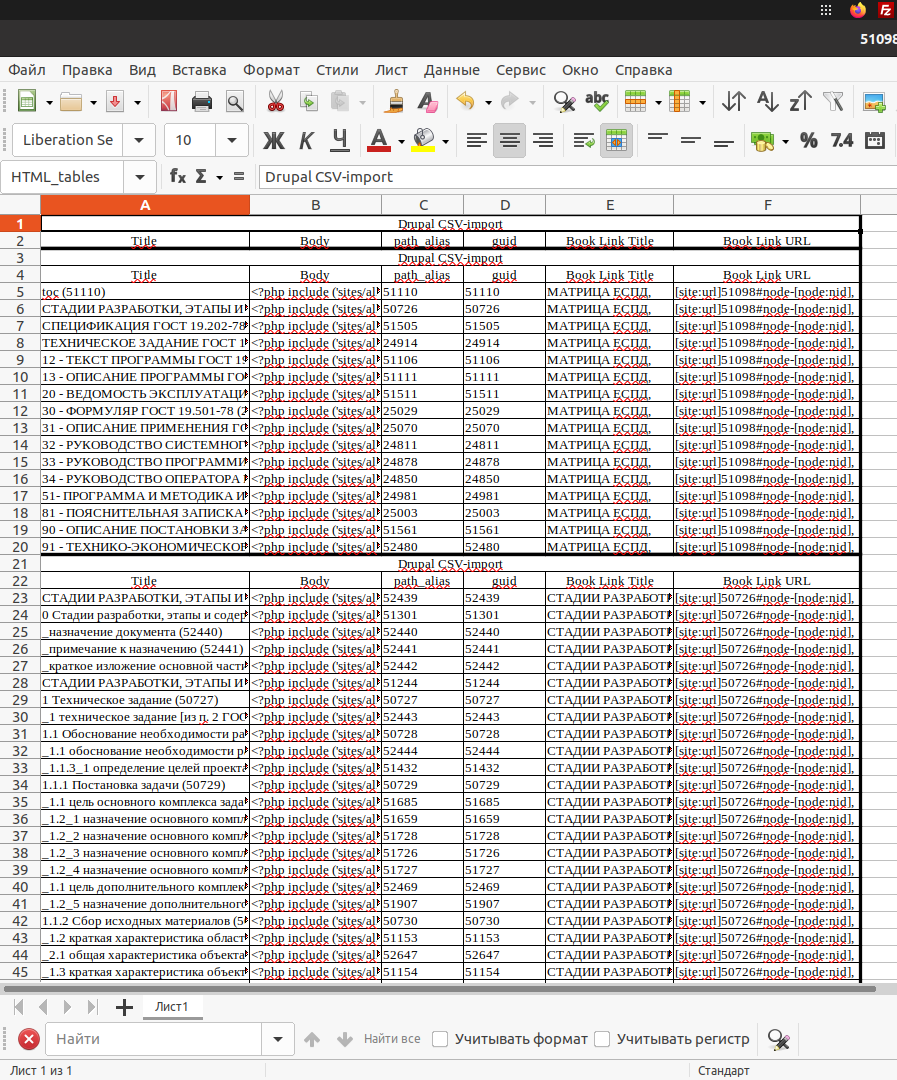
В этой табличке ячейки полей Body Link Title и Body Link URL содержат на хвосте запятые, добавляемые при XSLT–преобразовании. Из таблички удаляются строки сгруппированных полей Drupal CSV–импорт, после чего в новом листе создается сводная таблица.
Примечание — В табличке отсутствует набор полей для импорта в Jira, он есть, но пока закомментирован в XSLT–преобразовании за ненадобностью. При необходимости его легко включить и импортировать задачи в Jira целыми пакетами, сотнями и тысячами.
Итак, на рисунке ниже изображена разметка сводной таблицы.
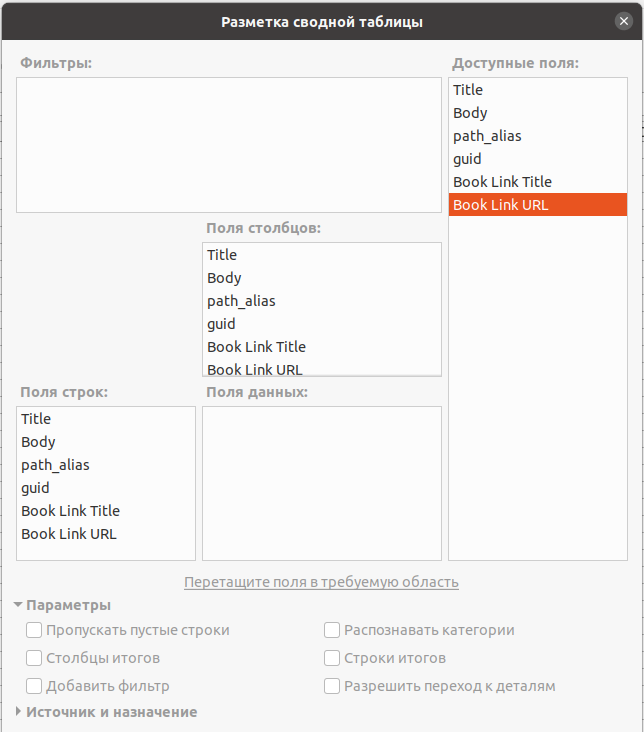
Просто и тупо, в ёкселе так не получится. На выходе отсортированная сводная таблица, см. рисунок ниже.
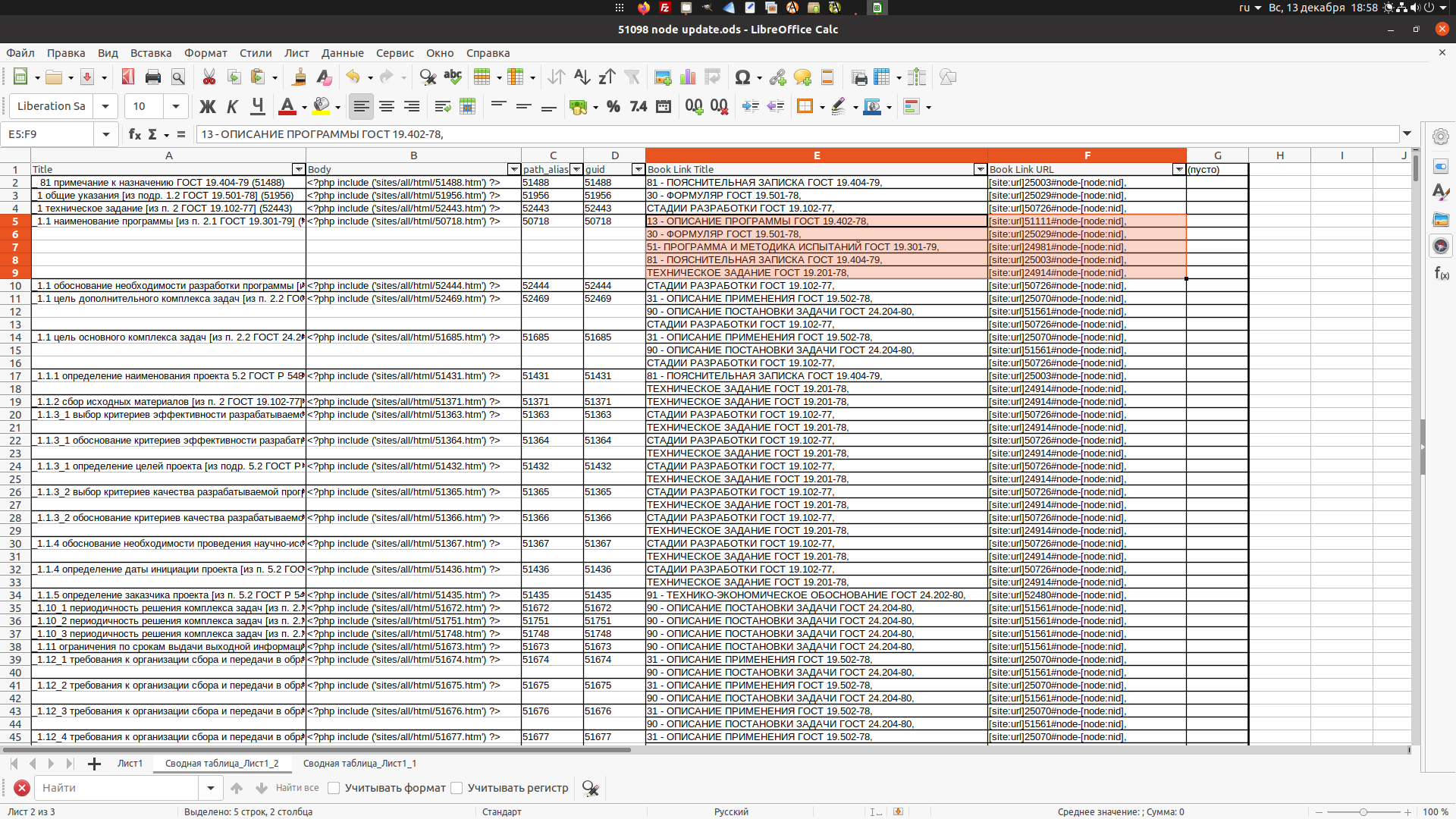
Выделены строки с топиком, который внедрен в структуры нескольких книг, в данном случае пяти. Соответствующие ячейки по столбцам должны быть объединены через запятую в одну строку, как изображено на рисунке ниже.
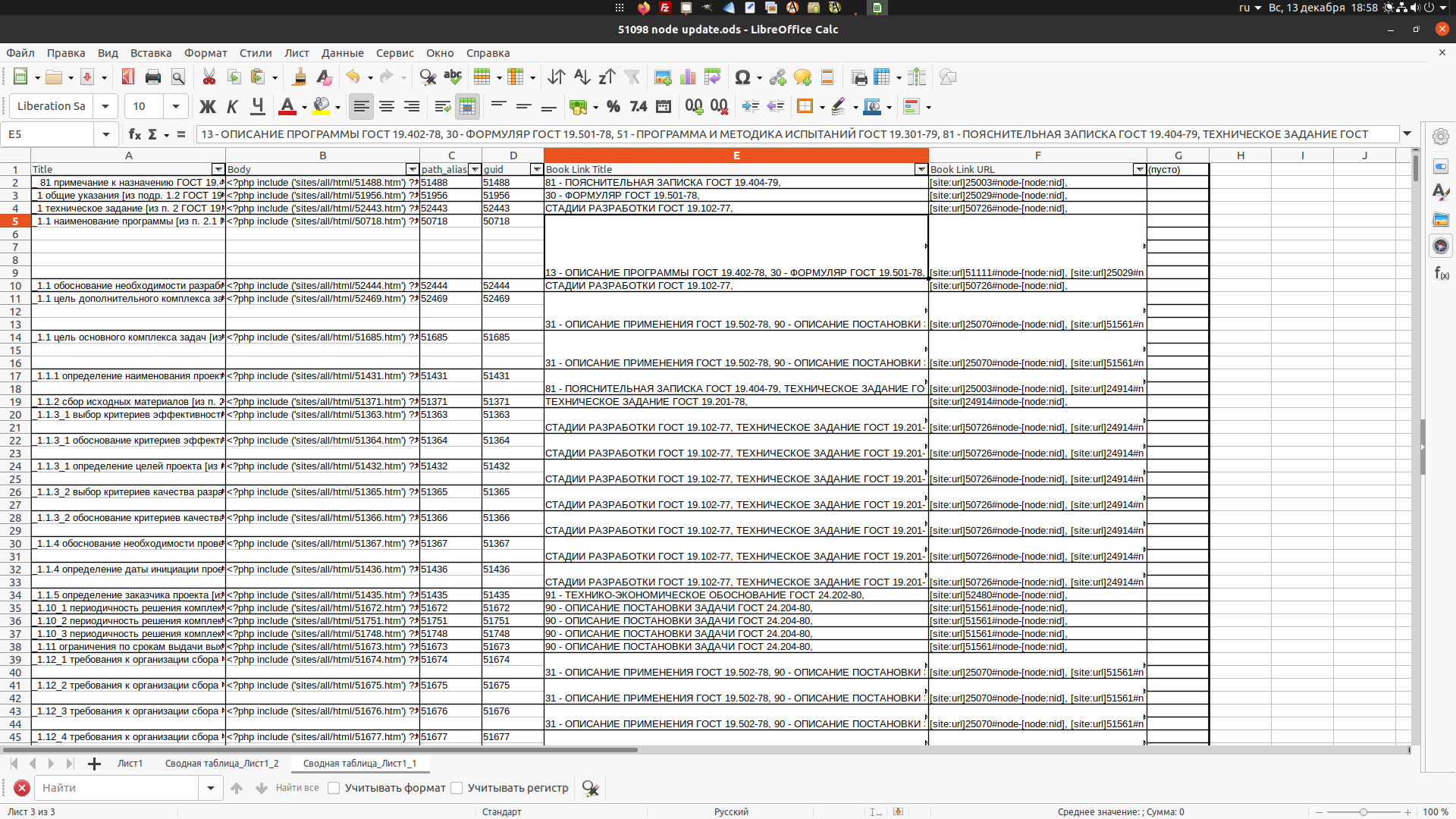
После указанного объединения табличка сохраняется в формате файла CSV, изображенного на рисунке ниже. При сохранении не забывать ставить флажок Текстовые значения в кавычках, это важно!
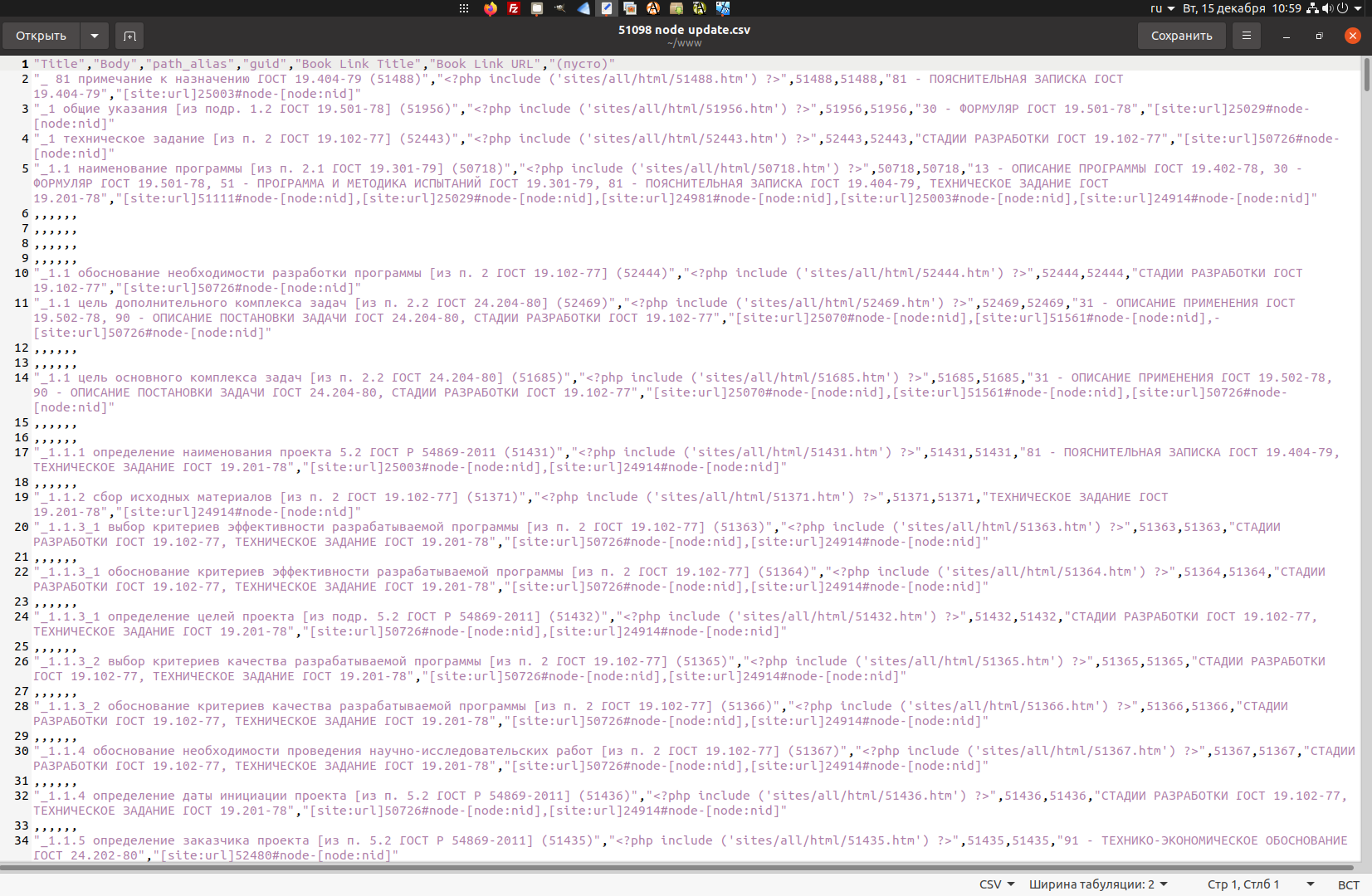
Это уже зачищенный вариант. Предварительно в файле надо сделать автозамены ,","[ на ","[ и ],", на ]" Удаляются также хвосты пусто и итог–результат. Множественные запятые не мешают.
После этого файл полностью готов к импорту в Drupal. Ничего не поделать, такова особенность CSV–импорта практически везде, вечная проблема с ограничениями в части зарезервированных символов.
Таблица book update
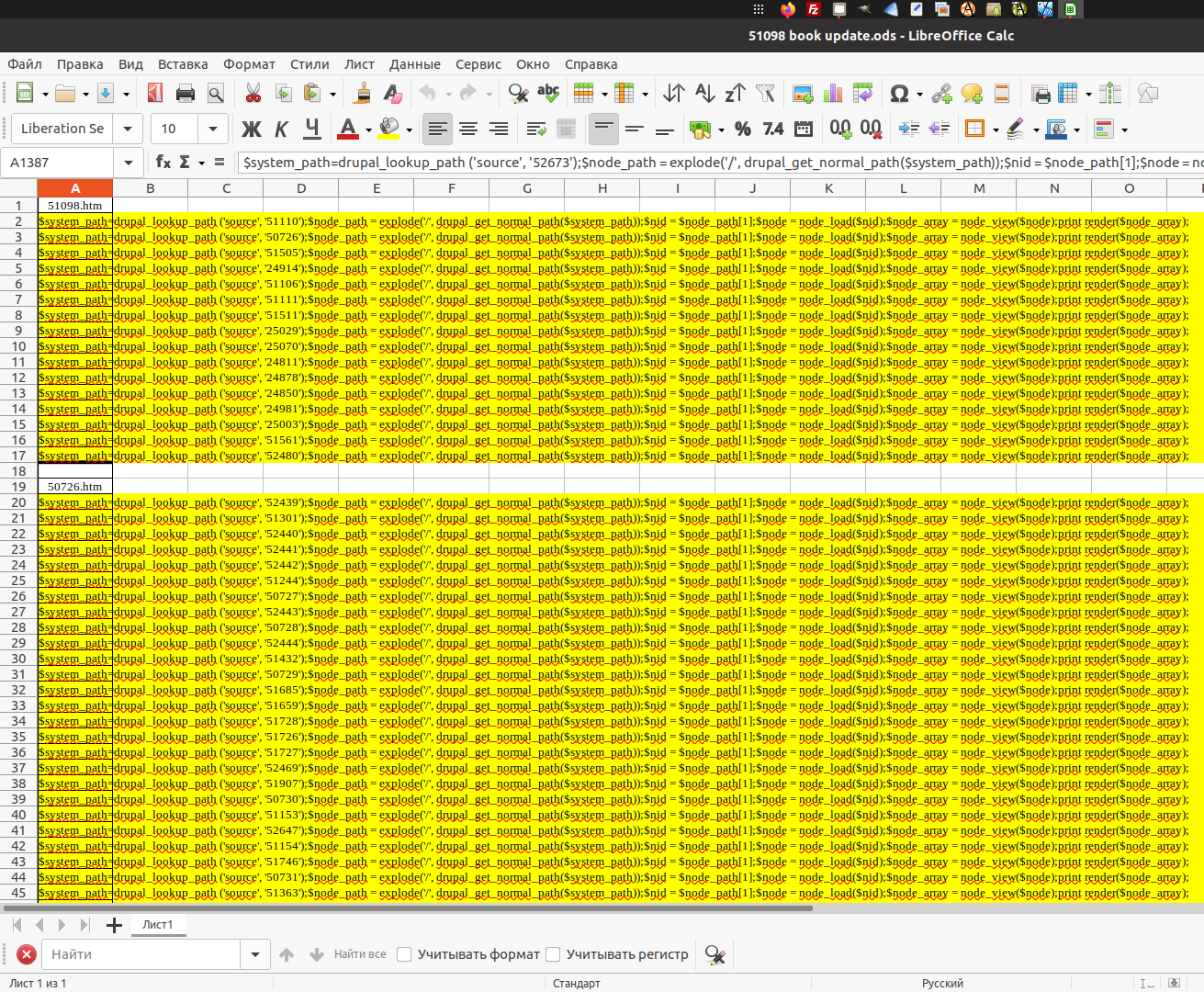
Таблица book update полностью готова для работы, не имеет смысла ее во что–то преобразовывать, проще копипастить непосредственно в файлы книг, имена которых расположены над выделенными областями. Сами файлы открываются для редактирования удаленно по FTP, выделенные области должны быть заключены в <?php ВЫДЕЛЕННАЯ ОБЛАСТЬ ?>. Начинать надо с самой топовой книги, в данном случае — с книги 51098.
Подготовка импортера Drupal
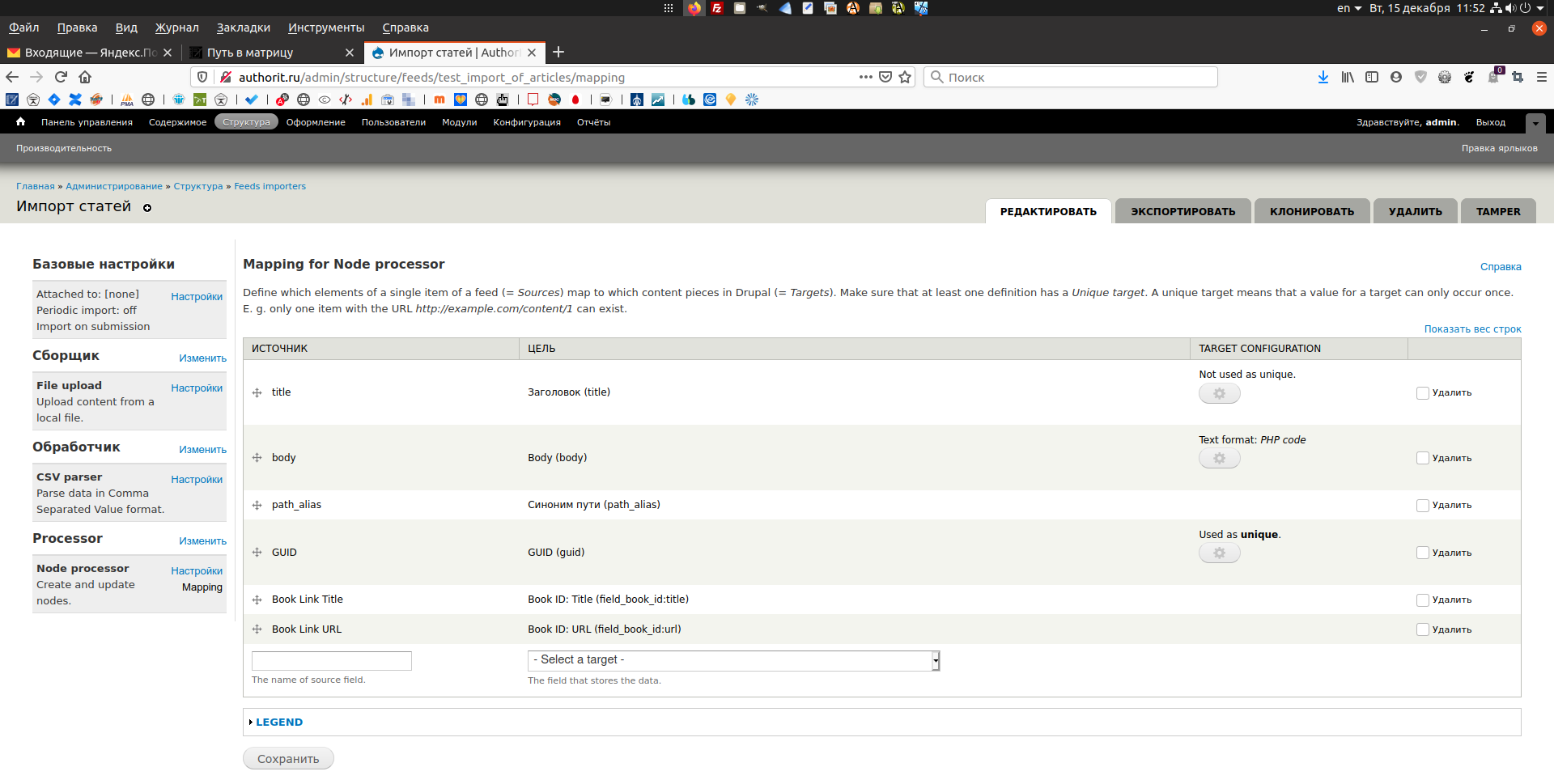
В чистовом варианте следует поменять названия целевых полей на Book Link. Теперь настройка тампера — включаются фильтры Explode, чтобы была возможность импортировать списки ссылок.
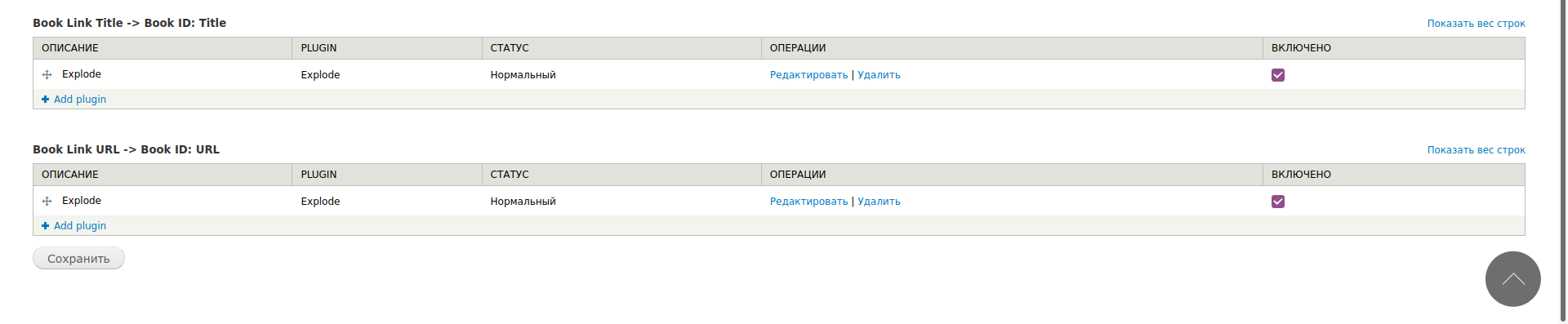
Вот и все, можно импортировать ноды с обновлением уже существующих.
